![]()
Lesson 2 Data Security
Pragmatic AI Labs
![]()
This notebook was produced by Pragmatic AI Labs. You can continue learning about these topics by:
- Buying a copy of Pragmatic AI: An Introduction to Cloud-Based Machine Learning
- Reading an online copy of Pragmatic AI:Pragmatic AI: An Introduction to Cloud-Based Machine Learning
- Watching video Essential Machine Learning and AI with Python and Jupyter Notebook-Video-SafariOnline on Safari Books Online.
- Watching video AWS Certified Machine Learning-Speciality
- Purchasing video Essential Machine Learning and AI with Python and Jupyter Notebook- Purchase Video
- Viewing more content at noahgift.com
Data Governance
AWS calls this knowledge domain Data Security, but a better title would be Data Governance. Security is one aspect of Governance and the exam does tend to focus on security quite a bit, but you will also encouter questions regarding other aspects of Data Governance.
I like this definition becuase it clearly defines data as an asset. Just like any other asset like property, vehicles, or livestock data has a value and therefore must be treated as valuable. The need for secuirty is obvious if you think of data as an asset. Just like you want to control who can enter your building and what they can do when they get there.
But notice the second part of that sentence: ‘Transformed into meaningful information’. What does that mean? Think of the data as a raw material like bauxite.
What is bauxite? Bauxite is a mineral ore that contains aluminum and other metals. It’s the main source of the worlds aluminum supply and is found in many places throughout the world. Bauxite must undergo several complex processes requiring chemistry and a large amount of electric power before it can become aluminum. Even then, aluminum is a “raw” material that needs to be made into the products we use. This complex set of processes is similar to Data Governance. Data Govenance is the set of processes that allow us to transform our raw data into finished information products.
Regulatory Requirements
Data is subject to regulation in many dimensions: Based on locality of data, locality of the user, content of the data, copyright… the list goes on and on. It can be very difficult to determine the regulatory requirements without some serious help. Luckily AWS has a suite of resources available to help.
The AWS Compliance Center The Compliance Center is the best place to begin investigating regulatory requirements by country. You can select a country from the map to generate a menu of FAQs and documents specific to that country.
The Compliance Center is the best place to begin investigating regulatory requirements by country. You can select a country from the map to generate a menu of FAQs and documents specific to that country.
Encryption
The AWS platform offers solutions for encypting data in transit and at rest.
Data in transit is typically protected with Transport Layer Security or it’s predecessor Secure Socket Layer. Data may also be protected in transit by using client side side encryption where data is encrypted BEFORE it traverses the network in a separate step.
TLS and SSL use x.509 certificates to exchange keys for encrpytion with the public key used to encrypt data and the private key used for decryption. All connections to the AWS APIs use TLS encrypted with certiticates signe by a public certificate authority. For example, all data transfer to S3 is encrypted in transit. You do not need to configure anything and it’s not possible to disable it. To secure network traffic to your OWN services AWS can issue certificates to your domain with the AWS Certificate Manager (ACM). ACM typically isn’t covered on the Big Data exam, but you should be aware that data into AWS is encrypted with TLS.
Many AWS storage and database services have several options for encrypting data at rest. The right option depends on the requiremnents presented and any regulatory compliance needed. We’ll cover encryption options in the sections for various services, but there are a few underlying technologies you should understand first.
Cloud HSM
Cloud HSM helps you meet corporate, contractual and regulatory compliance requirements for data security by using dedicated Hardware Security Module (HSM) instances within the AWS cloud. AWS offers a variety of solutions for protecting sensitive data within the AWS platform, but for some applications and data subject to contractual or regulatory mandates for managing keys, additional protection may be necessary. CloudHSM complements existing data protection solutions and allows you to protect your encryption keys within HSMs that are designed and validated to government standards for secure key management. CloudHSM allows you to securely generate, store and manage cryptographic keys used for data encryption in a way that keys are accessible only by you.
Dedicated HSM Single tennant Must provision cluster Must be provisioned inside VPC Works with on-premisis HSM
KMS
AWS KMS is a managed service that enables you to easily encrypt your data. AWS KMS provides a highly available key storage, management, and auditing solution for you to encrypt data within your own applications and control the encryption of stored data across AWS services.
Serverless Multi-tennant Works with Cloud HSM
Cloud Trail
CloudTrail provides visibility into user activity by recording actions taken on your account. CloudTrail records important information about each action, including who made the request, the services used, the actions performed, parameters for the actions, and the response elements returned by the AWS service. This information helps you to track changes made to your AWS resources and to troubleshoot operational issues. CloudTrail makes it easier to ensure compliance with internal policies and regulatory standards. For more details, refer to the AWS compliance white paper
AWS Shared Responsibility Model
One topic that you MUST understand to pass the AWS Big Data exam is the AWS Shared Responsibility Model. This has been covered on every AWS exam that I’ve ever taken. The good news is that the concepts are very simple to understand: You, as a solution designer have a certain amount of responsibility when it comes to ensuring data security. As an AWS customer you share this responsibility with AWS. The line of delinieation for that responsibility varies depending on the AWS services employed by the solution.
Model Variations
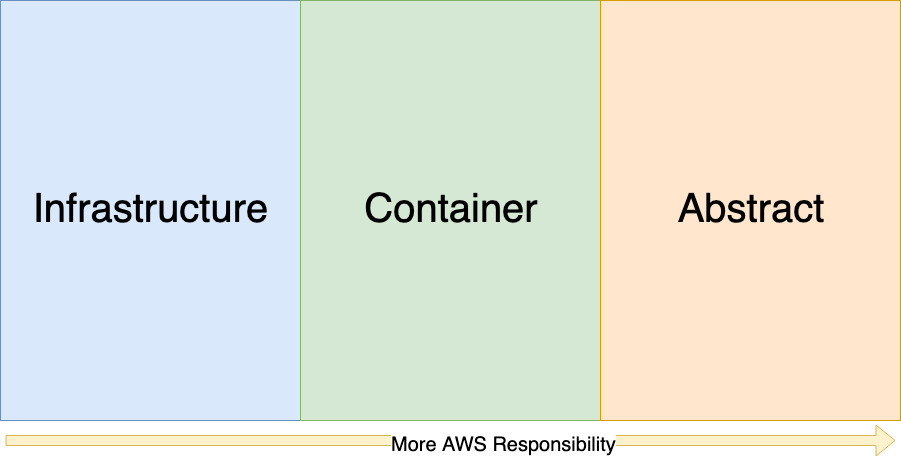
Shared Responsibility Model Overview
There are three major variations of the Shared Responsibility model.
- Infrastructure.
- Container.
- Abstract.
The amount of responsibilty for security reduces as you move to the right.
Infrastructure Model
- EC2
- EBS
- VPC
The infrastructure model applies to low level infrastructure service where the user has direct control over virtual hardware such as EC2 instances, EBS volumes, VPC networks and firewalls.
In the infrastructure model you are responsible for security at every level above the physical infrastrcucture. This includes.
Items to consider in this model are OS patching, data encryption (client, server, transport & at rest)
Most Big Data solutions on AWS will not use this model.
Infrastructure Model

Container Model
The container model applies to services wher AWS manages the underlying foundation services such as virtaul servers, networking, and storage.
For example the RDS service is responsible is for provisioning servers, networks, EBS volumes AND RDBMS software such as MySQL INCLUDING security patches. However you are still responsible for configuring firewall rules, user accounts, backups and recovery strategies.
This model is very common in Big Data solutions as it’s employed by EMR, Redshift, and other relevant services
As you can see the area of responsibility for AWS has grown while the Customer’s area has been reduced.
Container Model

Abstract Model
The Abstract model applies to all of the so called “serverless” service on the AWS platform. Abstract services are fully managed by AWS with resources provisioned automatically as needed.
These services manage access control entirely via AWS IAM (Covered in the next section).
Some of these services also offer options for encrpyting data at rest. For the Big Data exam it’s very important to understand which services offer this and what the options are for key management. We cover these services in some of the other modules, but the most important one to know is S3. S3 ALWAYS stores data encrypted at rest, however you can opt to have AWS manage the keys automatically, use a specific key in their Key Management Service, or to use a supplied encryption key. In the last case YOU are responsible for securing and retaining this key. If the key is lost it is IMPOSSIBLE to recover the data!
Some services covered by the Abstract Model are:
- S3
- DynamoDB
Abstract Model

AWS Access and Identity Management
AWS Access and Identity Management commonly known as IAM allows you to manage access to AWS services and resources securely.
Principle of Least Privilege


For any of the AWS exams it’s very improtant that you understand the Principal of Least Priviledge. The Principal of Least Priviledge simply states that a user or service should have access to ONLY the resources required to perform it’s legitimate purpose.
In this illustration there are two users with different job functions. The first user is a NOC operator responsible for monitoring the availability of the production environment. As part of his duties this user requires access to AWS Cloudwatch for Logs and metrics, and to EC2 to restart crashed instances or to increase capacity. He does not need access to DynamoDB tables becuase these contian sensitive user data. Any issues with DynamoDB will be reported through Cloudwatch. This users access should NOT include DynamoDB.
The second user is an application developer. This user also needs to access Cloudwatch Logs to diagnose bug reports and to make sure the application is running as expected. The developer DOES need access to DynamoDB in order to troubleshoot issues realted to schema design and index performance. The developer does NOT need to access EC2 as the operation of the servers is the responsibility of the NOC. The developer should not be granted access to EC2 instances.
IAM allows you to create a security policy that conforms to this principle easily. When considering any scenario on the test always keep in mind the minimum set of priviledges required to perform a given task.
There are 3 major resources you will interact with while configuring IAM:
- Users
- Groups
- Roles
Users

User Types

There are 2 distinct types of users in an AWS account:
- Root users
- IAM users
Each account has exactly one Root User. This user always has full privileges over all resources in the account. This account MUST be secured at all times and should NOT be used for day to day administrative or development tasks. The best practice for the root account is to immediately secure it with Multi Factor Authentication (MFA), disable any API keys associated with it and only use it in case of emergency (such as lockout of other accounts). That being said, there are a few tasks that can ONLY be performed by the root account such as changing your support plan or closing your account.
Groups

Groups are the simplest of the IAM objects. Groups are simply a collection of User objects. In fact IAM groups are even simpler than many other groups types becuase they can ONLY contain users directly… You cannot add a group to another group in AWS IAM.
Just becuase they’re simple doesn’t mean that groups aren’t important! You should almost always apply permissions to a group and add users to the group rather than applying permissions directly to a user. This makes it much simpler to manage permissions.
Roles

AWS IAM Roles are conceptually similar to Users: You can assign permission policies to a Role just like you can a user or group. However, instead of being associated with one person, a role is intended to be assumable by anyone who needs it. A role does not have standard long-term credentials such as a password or access keys. Instead, when you assume a role, it provides you with temporary security credentials for your role session.
Roles have a number of use cases in AWS:
Delegation is used to assign permission to an IAM account that they wouldn’t otherwise have. This is commonly used to grant access to a user from another AWS account. This is typical when there is a hierarchy of AWS accounts in an Organization.
Federation allows trust relationships to be formed with external account providers such as GSuite or Active Directory. Users defined in external account providers may be assigned to one or more Roles and granted access to AWS resources.
For the AWS Big Data Exam you probably don’t need to know much about Delegation or Federation. These use cases tend to be covered by the Architect or DevOps exams. Service and Service Linked Roles on the other hand must be understood to properly configure many of the Big Data services.
First, the definitions:
From the AWS documentation
“A Service Roles is role that a service assumes to perform actions in your account on your behalf. When you set up some AWS service environments, you must define a role for the service to assume. This service role must include all the permissions required for the service to access the AWS resources that it needs. Service roles vary from service to service, but many allow you to choose your permissions, as long as you meet the documented requirements for that service. Service roles provide access only within your account and cannot be used to grant access to services in other accounts. You can create, modify, and delete a service role from within IAM.”
So, a Service Role is simply a role that is assumed by an AWS service on your behalf. You are responsible for creating the role and configuring the permissions. The role must exist before the AWS service can be configured to use it.
A Service-Linked Role is an evolution of the Service Role. From the AWS docs:
“A unique type of service role that is linked directly to an AWS service. Service-linked roles are predefined by the service and include all the permissions that the service requires to call other AWS services on your behalf. The linked service also defines how you create, modify, and delete a service-linked role. A service might automatically create or delete the role. It might allow you to create, modify, or delete the role as part of a wizard or process in the service. Or it might require that you use IAM to create or delete the role. Regardless of the method, service-linked roles make setting up a service easier because you don’t have to manually add the necessary permissions.”
The Big Data services use a mix of Service Role and Service-Linked Roles in their respective configurations. The Big Data exam doesn’t ask directly about which services use Service-Linked Roles, but it does ofter ask detailed questions about configuring roles for these services, so it’s important to know the requirements for setting up each. We cover a few of these in detail in the next part of this lesson.
Redshift security
AWS Redshift is a fully managed data warehouse capable of analyzing petabytes of data on demand. We cover Redshift in depth in another section, but it’s important that you understand the security considerations before
Cluster management – The ability to create, configure, and delete clusters is controlled by the permissions given to the user or account associated with your AWS security credentials. AWS users with the proper permissions can use the AWS Management Console, AWS Command Line Interface (CLI), or Amazon Redshift Application Programming Interface (API) to manage their clusters. This access is managed by using IAM policies. For details, see Authentication and Access Control for Amazon Redshift.
Cluster connectivity – Amazon Redshift security groups specify the AWS instances that are authorized to connect to an Amazon Redshift cluster in Classless Inter-Domain Routing (CIDR) format. For information about creating Amazon Redshift, Amazon EC2, and Amazon VPC security groups and associating them with clusters, see Amazon Redshift Cluster Security Groups.
Database access – The ability to access database objects, such as tables and views, is controlled by user accounts in the Amazon Redshift database. Users can only access resources in the database that their user accounts have been granted permission to access. You create these Amazon Redshift user accounts and manage permissions by using the CREATE USER, CREATE GROUP, GRANT, and REVOKE SQL statements. For more information, see Managing Database Security.
Temporary database credentials and single sign-on – In addition to creating and managing database users using SQL commands, such as CREATE USER and ALTER USER, you can configure your SQL client with custom Amazon Redshift JDBC or ODBC drivers. These drivers manage the process of creating database users and temporary passwords as part of the database logon process.
The drivers authenticate database users based on AWS Identity and Access Management (IAM) authentication. If you already manage user identities outside of AWS, you can use a SAML 2.0-compliant identity provider (IdP) to manage access to Amazon Redshift resources. You use an IAM role to configure your IdP and AWS to permit your federated users to generate temporary database credentials and log on to Amazon Redshift databases. For more information, see Using IAM Authentication to Generate Database User Credentials.